







")
 Main objectives: Computer Vision is a field that includes methods for acquiring, processing, analyzing in order to understand images. Understanding image is a real scientific challenge which presents a lot of open problems. Objectives of our Computer Vision Department are not do deal with all of these problems but to focus on:
Main objectives: Computer Vision is a field that includes methods for acquiring, processing, analyzing in order to understand images. Understanding image is a real scientific challenge which presents a lot of open problems. Objectives of our Computer Vision Department are not do deal with all of these problems but to focus on:
• Realizing fundamental researches in visual feature extraction and object representation by introducing new types of feature and/or by combining with other types of feature (multimodal approach);
• Developing real vision based applications, particularly for Vietnam.
Thus the purpose of the Computer Vision Department is twofold. The first one aims assisting the development of Vietnam in areas such as tourism aid, heritage preservation, biodiversity conservation. The second one tries to catch up international level of research in image and video analysis.
Research tasks and activities: the “Computer Vision” department’s activities are pursued following two main scientific motivations:
 Understanding image and videos: nowadays, with the increasing of technology, cameras are integrated inside many accessories (mobile phone, tablets) or installed at many places (office, store, factories) that make capturing photos, video sequences of everyday life become easier. Although since several decencies, researchers on the world have made a lot of contributions in image / video analysis, automatic understanding of the content of images / videos remains still a real challenge. This comes from the large number of objects in the world, the nature of these objects (fixed / mobile objects, deformable / rigid objects) and the environment as well as the interaction between objects and environment. In addition, as the cameras can be installed at multiple places, the same objects observed at different views may appear very different in the image. Moreover, with the development of technologies, camera could see objects in a larger range of the visible light spectrum (hyper spectral imagine) or the integration of other sensors inside a camera providing easily and low-cost depth information of the object. Understanding image and videos requires fundamental researches on representing object classes in a compact, efficient and discriminated manner, on detecting and tracking multiple objects in the scene and on modeling and recognizing activities in videos. The originality of our researches is to extract features from different data (RGB pr Depth an so on) captured from one or multiple cameras as well as the context information for object and activity/event representation.
Understanding image and videos: nowadays, with the increasing of technology, cameras are integrated inside many accessories (mobile phone, tablets) or installed at many places (office, store, factories) that make capturing photos, video sequences of everyday life become easier. Although since several decencies, researchers on the world have made a lot of contributions in image / video analysis, automatic understanding of the content of images / videos remains still a real challenge. This comes from the large number of objects in the world, the nature of these objects (fixed / mobile objects, deformable / rigid objects) and the environment as well as the interaction between objects and environment. In addition, as the cameras can be installed at multiple places, the same objects observed at different views may appear very different in the image. Moreover, with the development of technologies, camera could see objects in a larger range of the visible light spectrum (hyper spectral imagine) or the integration of other sensors inside a camera providing easily and low-cost depth information of the object. Understanding image and videos requires fundamental researches on representing object classes in a compact, efficient and discriminated manner, on detecting and tracking multiple objects in the scene and on modeling and recognizing activities in videos. The originality of our researches is to extract features from different data (RGB pr Depth an so on) captured from one or multiple cameras as well as the context information for object and activity/event representation.
Vision based human - machine interaction: at this era, research results in computer vision have came out laboratories and appear in several commercial products to serve human in a everyday life (automatic surveillance system, service robot, surface defect detection system, remote control, etc.). One of our interests is to make these products more usable and familiar for different types of user.
We prefer that the interaction between human and machine should approach the interaction between human and human. To obtain this ambitious objective, we need to study the behavior of human in interacting with machine and then define human - machine interaction protocol. We focus our researches on using multiple channels of communication such as gesture, emotion, voice, specifically aiming at providing a complementary modality for auditory modality for human-machine interaction: visual modality.

|
|||||||||||||||||



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Projects in process
- VLIR research program - VIPPA (Visually Impaired People Assistance using multimodal technologies)
- Nafosted-FW0 (Geometric scene analysis as a navigational aid to the visually impaired)
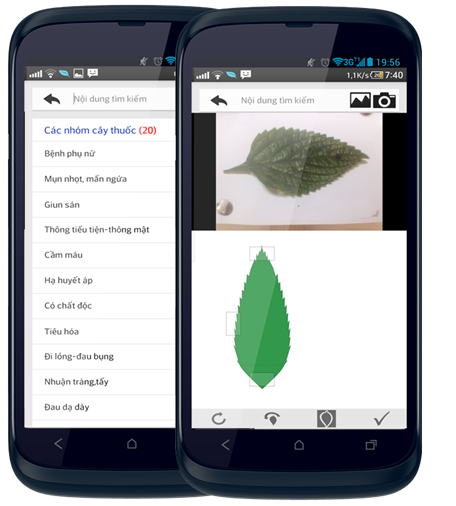
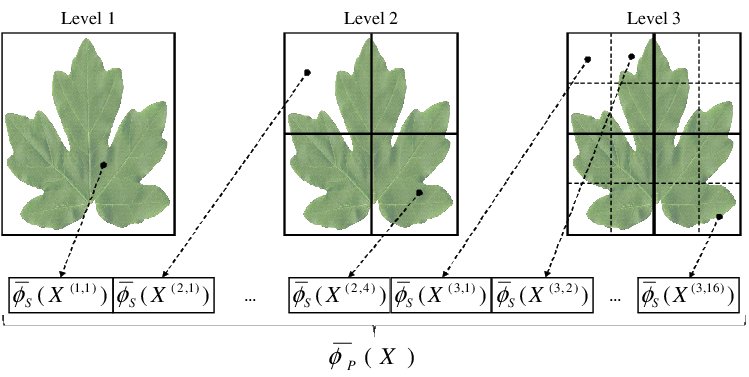
- AUN/SEED-Net project (Medicinal Plant Identification and Collaborative Information System)
- CUI research program (Rice seed assessment using advanced image processing techniques and machine vision tool)
Completed projects
- MOET project (Abnormal event detection using Kinect)
- MOET project (Object detection and recognition in ambient environment)
- LORELA (Localisation Relative personnes/objets en environnements perceptifs pour l'assistance aux personnes Aveugles)
- SYSAPA (Système de Surveillance pour l'Assistance des Personnes Aveugles en
environnement perceptifs)
- CUI research program (Automatizing tea flush assessment by advanced machine vision technique)
- SMART ROBOT (Smart robot guide in museum using multimodal technology)
- AFDD (Automated Fabric Defect Detection system)
- MARVEL (Multimodal Analysis of Recorded Video for E-Learning)
- IRIS (Indexation et Reconnaissance d’Images par la Sémantique)
- SEPIA (Système d’Etude du Patrimoine des Inscriptions Anciennes
du Vietnam)
- MOSAIC (Mobile Search and Annotation using Images in Context)
Contacts
Le Thi Lan (Director) – thi-lan.le at mica.edu.vn
Tran Thi Thanh Hai (Vice-Director) – thanh-hai.tran at mica.edu.vn
Vu Hai (researcher) – hai.vu at mica.edu.vn
| Partners Naiscorp Ltd. (Vn) Norfold Hatexco Ltd. (Vn) Hanoi University of Agriculture (Vn) Thai Nguyen University (Vn) Danang University of Technology (Vn) Nguyen Dinh Chieu School (Vn) EFEO (Vn) NOMAFSI (Vn) INRIA Sophia Antipolis (Fr) L3I (Fr) |
LIG (Fr) CIRAD (Fr) IMEP- LAHC (Fr) ORANGE (Fr/Jp) NII (Jp) Ghent University (Be) University of Strathclyde, Glasgow (UK) Osaka University (Jp) KMITL (Thailand) |
page updated July 14, 2016
Vietnam landscape view
