In order to build a dataset for person re-identification, we use the building of our office (see Fig. 1) and prepare two different scripts.
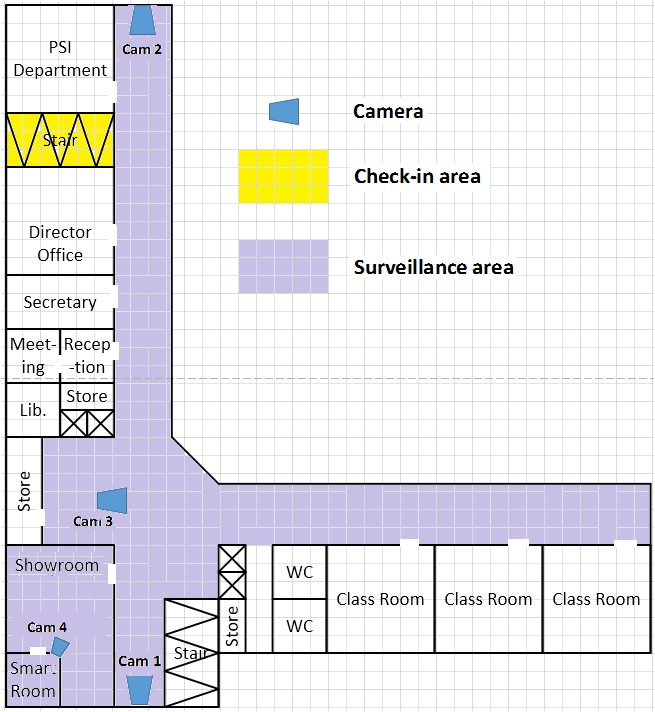
Fig1: Environment used for person re-identification dataset
Script for MICA1 dataset
In this script, the test-ing environment is divided into two regions: check-in and surveillance. In the
check-in region, one camera deployed at the entrance of the stair area is used to capture images for training individual descriptor for each person.
Each person will move in the FOV of the entrance camera so that the human
appearances are captured from as many camera viewpoints as possible.
There are 25 people for the this script. These people moved in different routes
in the testing environment and their appearance images are extracted at different scales and poses (see Fig. 2).
For this dataset, we extract manually person ROIs (Region of Interest). As results, MICA1 dataset has two folders:
- training (23.1MB with 1550 images for 25 people)
- testing (22.6MB with 4103 images for 25 people)

Fig2: Examples in the MICA1 dataset. The images on the top are captured from a camera at check-in region and used for training phase. The images at the bottom are the testing images which acquired from 4 other cameras (Cam1, Cam2, Cam3, Cam4) in surveillance region.
Script for MICA2 datasetThe second script called MICA2 is set with three cameras in the surveillance area (Cam1, Cam2, Cam4 in Fig.1).
It is different from script one, the human ROIs which are manually cropped from the images captured by Cam2 are processed for the training phase (see Fig. 3).
The testing phase is done with the human ROIs extracted manually and automatically from the images captured by Cam1 and Cam4. MICA2 contains images of 40 people. For MICA2 dataset, we extract both manually and automatically person ROIs (Region of Interest). As results, MICA2 dataset has three folders:
- training with manually cropped ROI(55.9MB with 3480 images for 40 people)
- testing with manally cropped ROI (67.5MB with 6812 images for 40 people)
- testing with automatically extracted ROI (2.04GB with 75080 images for 40 people)

Fig3: Examples of images captured with Cam2 in the MICA2 dataset.
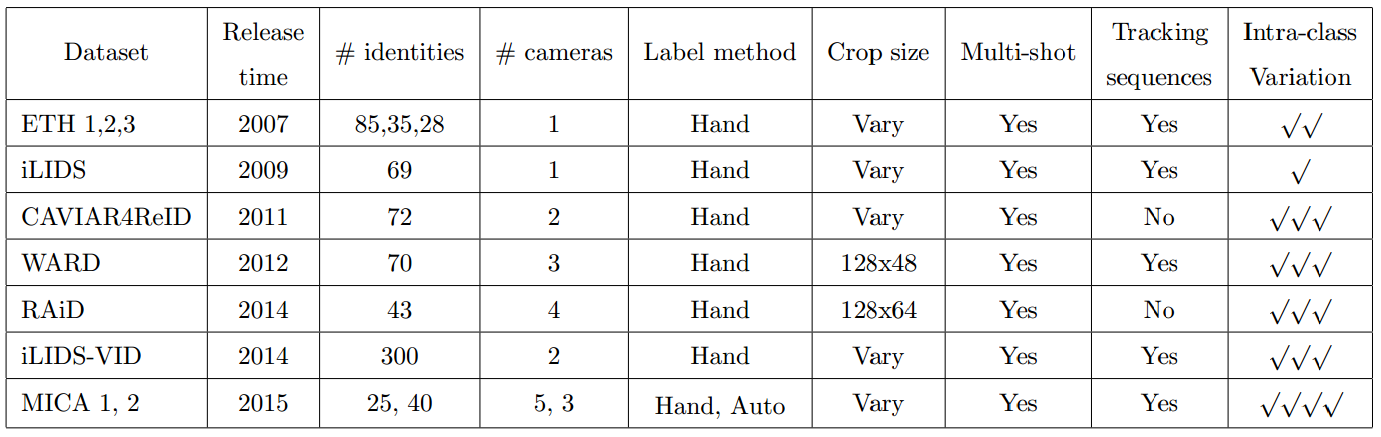
Fig4: Comparison of our dataset with the existing datasetes.
Download:Our dataset is available and free for research purpose. If you want to use our dataset, please contact me (email: Thi-Lan.Le@mica dot edu dot vn).